[V8 Deep Dives] Map의 내부 구조 이해하기
📚 V8 Deep Dives Series
- 1.[V8 Deep Dives] Map의 내부 구조 이해하기 (현재 글)
- 2.[V8 Deep Dives] Array의 내부 구조 이해하기
- 3.[V8 Deep Dives] Math.random()에 대한 무질서한 생각들
- 4.[V8 Deep Dives] Object와 Map의 차이점 완전 분석
이 글은 Andrey Pechkurov의 원문(V8 Deep Dives: Understanding Map Internals)을 저자의 허락을 받고 번역한 글입니다.
이 글은 V8 Deep Dives 시리즈의 첫 번째 글입니다. V8 엔진을 직접 실험하면서 알게 된 내용을 정리했습니다. 읽고 나서 다음 주제에 대한 아이디어가 있으시면 공유해주세요.
들어가며
ES6(ECMAScript 2015)는 Map, Set, WeakMap, WeakSet 같은 내장 컬렉션을 도입했습니다. 이 컬렉션들은 라이브러리, 애플리케이션, Node.js 코어에서 폭넓게 사용되고 있습니다. 이 글에서는 그중 Map에 집중해서 V8이 어떻게 구현했는지 살펴보고, 실무에 적용할 수 있는 결론을 도출해보겠습니다.
ECMAScript 명세는 Map을 어떻게 구현해야 하는지 구체적으로 정하지 않습니다. 대신 다음과 같은 힌트만 제공합니다:
Map 객체는 해시 테이블이나, 요소 수에 대해 평균적으로 sublinear한 접근 시간을 제공하는 메커니즘으로 구현해야 한다. 이 명세의 자료구조는 Map 객체의 관찰 가능한 동작을 설명하기 위한 것일 뿐, 실제 구현 모델을 의도한 것이 아니다.
명세는 JS 엔진에 상당한 자유를 줍니다. 알고리즘, 성능, 메모리 사용량 모두 엔진 구현자에게 맡깁니다. 만약 여러분의 코드가 hot path에서 Map을 사용하거나, Map에 대량의 데이터를 저장한다면 내부 구현을 이해하는 것이 도움이 됩니다.
저는 Java를 주로 써왔는데, Java에서는 Map 인터페이스의 구현체를 여러 개 중에서 선택할 수 있고 필요하면 세부 튜닝도 할 수 있습니다. 표준 라이브러리의 소스 코드도 언제든 열어볼 수 있죠. 그래서 V8의 Map이 내부적으로 어떻게 동작하는지 궁금해서 직접 파보게 되었습니다.
참고: 이 글은 Node.js 개발 버전(commit 238104c)에 포함된 V8 8.4 기준입니다. 구현 세부사항은 버전에 따라 달라질 수 있으니, 명세에 정의된 동작 외에는 보장되지 않습니다.
기본 알고리즘
V8의 Map은 해시 테이블(hash table)을 기반으로 합니다. 이 글은 해시 테이블의 기본 개념을 알고 있다고 가정하고 진행하겠습니다. 익숙하지 않다면 위키피디아 문서를 먼저 읽어보시길 권합니다.
Map을 써본 분이라면 여기서 의문이 생길 수 있습니다. 일반적인 해시 테이블은 순회 순서를 보장하지 않습니다. 그런데 ES6 명세는 Map을 순회할 때 삽입 순서를 유지하도록 요구합니다. 그렇다면 기존의 해시 테이블 알고리즘으로는 Map을 구현할 수 없는 걸까요?
V8은 Tyler Close가 제안한 결정적 해시 테이블(deterministic hash table) 알고리즘을 사용해서 이 문제를 해결합니다. 핵심 자료구조를 TypeScript로 표현하면 다음과 같습니다:
interface CloseTable {
hashTable: number[];
dataTable: Entry[];
nextSlot: number;
}
interface Entry {
key: any;
value: any;
chain: number;
}CloseTable이 해시 테이블 전체를 나타냅니다. hashTable 배열의 크기는 버킷(bucket) 수와 같고, 각 원소는 해당 버킷의 첫 번째 entry가 dataTable의 어느 위치에 있는지를 가리킵니다.
dataTable은 entry를 삽입 순서대로 저장합니다. 각 entry의 chain 속성은 같은 버킷에 속하는 다음 entry를 가리킵니다. 단일 연결 리스트(singly linked list) 구조입니다.
새 entry를 삽입하면 dataTable의 nextSlot 위치에 저장됩니다. 해당 버킷의 체인이 갱신되어 새 entry가 꼬리(tail)가 됩니다.
entry를 삭제하면 dataTable에서 해당 위치가 비워집니다(예: undefined로 설정). 여기서 중요한 점은 삭제된 entry도 dataTable에서 공간을 계속 차지한다는 것입니다.
테이블이 entry로 가득 차면(삭제된 것 포함) 리해싱(rehashing)이 필요합니다. 더 크거나 작은 새 테이블을 만들어서 데이터를 옮깁니다.
이 방식의 핵심은 Map을 순회할 때 그냥 dataTable을 처음부터 끝까지 돌면 된다는 것입니다. 삽입 순서가 자연스럽게 보장됩니다. 아마 대부분의 JS 엔진이 비슷한 방식을 쓸 것으로 예상됩니다.
예제로 살펴보기
알고리즘이 실제로 어떻게 동작하는지 예제를 통해 알아보겠습니다. 버킷 2개(hashTable.length), 총 용량 4개(dataTable.length)인 CloseTable에 다음과 같이 데이터를 넣는다고 가정합니다:
table.set(0, 'a'); // => 버킷 0 (0 % 2)
table.set(1, 'b'); // => 버킷 1 (1 % 2)
table.set(2, 'c'); // => 버킷 0 (2 % 2)이 예제에서 내부 테이블 표현은 다음과 같습니다:
hashTable dataTable
┌────────┬──────┐ ┌──────┬─────┬───────┬───────┐
│ bucket │ head │ │ slot │ key │ value │ chain │
├────────┼──────┤ ├──────┼─────┼───────┼───────┤
│ 0 │ 0 ──┼────────▶│ 0 │ 0 │ 'a' │ 2 ──┼──┐
├────────┼──────┤ ├──────┼─────┼───────┼───────┤ │
│ 1 │ 1 ──┼────────▶│ 1 │ 1 │ 'b' │ -1 │ │
└────────┴──────┘ ├──────┼─────┼───────┼───────┤ │
│ 2 │ 2 │ 'c' │ -1 │◀─┘
├──────┼─────┼───────┼───────┤
│ 3 │ │ │ │ ← nextSlot
└──────┴─────┴───────┴───────┘
버킷 0의 체인: hashTable[0] → slot 0 (chain: 2) → slot 2 (chain: -1, 끝)
table.delete(0)을 호출해서 entry를 삭제하면 테이블은 다음과 같이 변합니다:
hashTable dataTable
┌────────┬──────┐ ┌──────┬─────┬───────┬───────┐
│ bucket │ head │ │ slot │ key │ value │ chain │
├────────┼──────┤ ├──────┼─────┼───────┼───────┤
│ 0 │ 2 ──┼──┐ │ 0 │ ~~~ │ ~~~ │ ~~~ │
├────────┼──────┤ │ ├──────┼─────┼───────┼───────┤
│ 1 │ 1 ──┼──┼─────▶│ 1 │ 1 │ 'b' │ -1 │
└────────┴──────┘ │ ├──────┼─────┼───────┼───────┤
└─────▶│ 2 │ 2 │ 'c' │ -1 │
├──────┼─────┼───────┼───────┤
│ 3 │ │ │ │ ← nextSlot
└──────┴─────┴───────┴───────┘
삭제된 slot 0은 빈 공간으로 남지만, nextSlot은 여전히 3입니다. 삭제된 공간은 재사용되지 않습니다.
여기서 entry를 두 개 더 삽입하면 해시 테이블에 리해싱이 필요해집니다. 이 과정은 뒤에서 더 자세히 다루겠습니다.
같은 알고리즘이 Set에도 적용됩니다. 유일한 차이점은 Set의 entry에는 value 속성이 필요 없다는 것입니다.
이제 Map 뒤에 있는 알고리즘을 이해했으니, 더 깊이 들어가 볼 준비가 되었습니다.
구현 세부사항
V8에서 Map은 C++로 구현되어 있고 JS API로 노출됩니다. 핵심 코드는 OrderedHashTable과 OrderedHashMap 클래스에 있습니다. 직접 코드를 읽어보고 싶다면 다음 파일들을 참고하세요:
ordered-hash-table.hordered-hash-table.ccbuiltins-collections-gen.cc
이제 실무에서 중요한 세부사항들을 하나씩 살펴보겠습니다.
용량(Capacity)
V8에서 해시 테이블의 용량은 항상 2의 거듭제곱입니다. 적재율(load factor)은 2로 고정되어 있어서, 최대 용량은 버킷 수 × 2입니다.
빈 Map을 생성하면 버킷이 2개입니다. 따라서 초기 용량은 4개입니다.
최대 용량 제한도 있습니다. 64비트 시스템에서는 (약 1,670만)개까지만 저장할 수 있습니다. 이 제한은 Map의 힙 메모리 표현 방식 때문입니다.
테이블을 늘리거나 줄일 때는 2배 단위로 변경합니다. Map에 entry가 4개 있을 때 하나를 더 추가하면 리해싱이 발생하고, 버킷이 4개인 새 테이블이 만들어집니다.
직접 확인해보기 위해 V8을 수정해서 버킷 수를 buckets 속성으로 노출해봤습니다. 수정된 Node.js로 다음 스크립트를 실행하면:
const map = new Map();
let prevBuckets = 0;
for (let i = 0; i < 100; i++) {
map.set(i, i);
if (prevBuckets != map.buckets) {
console.log(`size: ${map.size}, buckets: ${map.buckets}`);
prevBuckets = map.buckets;
}
}출력 결과:
size: 1, buckets: 2
size: 5, buckets: 4
size: 9, buckets: 8
size: 17, buckets: 16
size: 33, buckets: 32
size: 65, buckets: 64
용량에 도달할 때마다 버킷이 2배로 늘어나는 것을 확인할 수 있습니다.
반대로 삭제할 때는 어떨까요?
for (let i = 99; i >= 0; i--) {
map.delete(i);
if (prevBuckets != map.buckets) {
console.log(`size: ${map.size}, buckets: ${map.buckets}`);
prevBuckets = map.buckets;
}
}출력 결과:
size: 31, buckets: 32
size: 15, buckets: 16
size: 7, buckets: 8
size: 3, buckets: 4
size: 1, buckets: 2
남은 entry가 버킷 수 / 2보다 적어지면 테이블이 절반으로 줄어듭니다.
해시 함수
V8이 키의 해시 코드를 어떻게 계산하는지도 알아두면 좋습니다.
숫자 타입(Smi, 힙 숫자, BigInt 등)은 충돌 확률이 낮은 해시 함수를 사용합니다.
문자열 타입(문자열, 심볼)은 문자열 내용을 기반으로 해시 코드를 계산하고, 내부 헤더에 캐시해둡니다.
객체는 난수를 기반으로 해시 코드를 생성하고, 역시 내부 헤더에 캐시합니다.
시간 복잡도
set, delete 같은 Map 연산은 대부분 조회(lookup)를 필요로 합니다. 일반적인 해시 테이블과 마찬가지로 조회의 시간 복잡도는 입니다.
최악의 경우를 생각해봅시다. 테이블이 가득 찼고, 모든 entry가 하나의 버킷에 몰려 있고, 찾는 entry가 체인의 맨 끝에 있습니다. 이 경우 번의 체인 이동이 필요합니다.
반면 최선의 경우는 테이블이 가득 찼지만 각 버킷에 entry가 2개씩 고르게 분포되어 있을 때입니다. 최대 2번의 이동으로 찾을 수 있습니다.
개별 연산은 빠르지만, 리해싱은 다릅니다. 리해싱은 이고 힙에 새 테이블을 할당해야 합니다. 리해싱은 삽입이나 삭제 도중에 발생하므로, map.set() 한 번이 예상보다 오래 걸릴 수 있습니다. 다행히 리해싱은 자주 일어나지 않습니다.
메모리 사용량
해시 테이블은 힙의 backing store에 저장됩니다. 여기서 흥미로운 점은 테이블 전체가 고정 길이 배열 하나에 들어간다는 것입니다. 레이아웃은 다음과 같습니다:
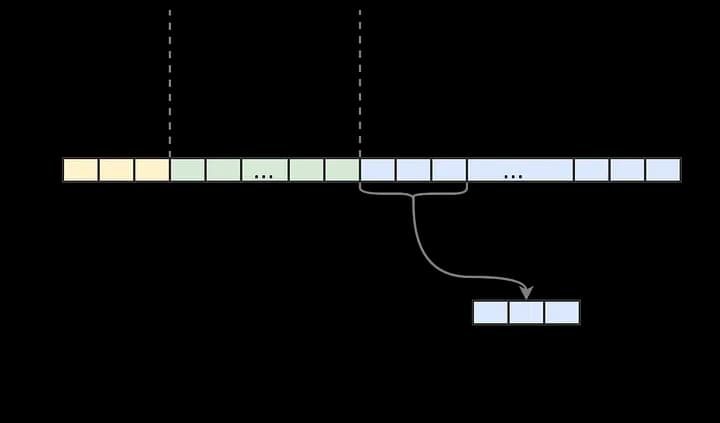
헤더에는 버킷 수, 삭제된 entry 수 같은 메타 정보가 들어갑니다. 각 entry는 배열 원소 3개를 차지합니다: 키, 값, 체인 포인터.
배열 크기는 대략 로 추정할 수 있습니다(은 테이블 용량).
64비트 시스템에서 포인터 압축이 꺼져 있다고 가정하면, 배열 원소 하나는 8바이트입니다. 용량이 (약 100만)인 Map은 대략 29MB의 힙 메모리를 사용합니다.
정리
V8의 Map에 대해 알아본 내용을 정리하면 다음과 같습니다:
- V8은 결정적 해시 테이블 알고리즘으로 Map을 구현합니다. 다른 JS 엔진도 비슷할 가능성이 높습니다.
- Map은 C++로 구현되어 있고 JS API로 노출됩니다.
- 조회는 , 리해싱은 입니다.
- 64비트 시스템에서 포인터 압축이 꺼진 경우, 100만 entry Map은 약 29MB를 차지합니다.
- 위 내용은 Set에도 대부분 적용됩니다.
다음에는 Array의 내부 구조를 다뤄볼까 생각 중입니다. 다른 주제 제안도 환영합니다.